In the cutting-edge realm of machine learning, tokenization emerges as a pivotal technique that transforms raw text into actionable data. But what exactly is tokenization in machine learning, and why is it indispensable? Imagine enhancing your Natural Language Processing (NLP) model’s accuracy by effectively parsing complex text data this is the transformative power of tokenization. Consider a data scientist working on a sentiment analysis project: without effective tokenization, the model struggles to understand nuances in customer reviews, leading to inaccurate sentiment predictions.
This comprehensive guide delves deep into the use of tokenization in machine learning, exploring its definition, importance, various techniques, challenges, tools, applications, best practices, and future trends. Whether you’re a seasoned data scientist or just embarking on your NLP journey, mastering tokenization is essential for building robust and efficient ML models that excel in understanding and generating human language.
What is Tokenization?
Beyond text analysis, tokenization is increasingly applied in areas like finance, where it represents real-world assets as digital tokens on blockchain networks.
Definition and Explanation
Tokenization is the foundational process of breaking down text into smaller units known as tokens. These tokens can be words, subwords, characters, or even sentences, depending on the chosen tokenization technique. At its core, tokenization serves as the gateway for converting unstructured text data into a structured format that machine learning models can effectively process and analyze.

Tokenization is the first and one of the most critical steps in the NLP pipeline. By segmenting text into manageable pieces, tokenization allows machine learning algorithms to handle and interpret textual data more efficiently. Without tokenization, models would be overwhelmed by the complexity and variability of natural language, making tasks like classification, translation, and sentiment analysis nearly impossible.
Role in Text Preprocessing
Tokenization plays a crucial role in simplifying complex text data, making it more manageable for analysis and modeling. By converting unstructured text into structured tokens, machine learning algorithms can efficiently process and learn from the data. This transformation is vital for various NLP tasks, including sentiment analysis, machine translation, and text classification, enabling models to discern patterns and extract meaningful insights from vast amounts of textual information.
Imagine trying to analyze a novel without breaking it down into sentences or words. The task would be overwhelmingly complex and inefficient. Tokenization addresses this by segmenting text into logical units, providing a structured foundation for further preprocessing steps like normalization, lemmatization, and feature extraction.
Why is Tokenization Important in Machine Learning?
Tokenization is not merely a preprocessing step; it’s a fundamental component that significantly influences the performance and effectiveness of machine learning models in NLP. Here’s why tokenization is indispensable:
Data Preparation
Tokenization transforms unstructured text into a structured format, enabling machines to interpret and analyze the data effectively. Without tokenization, raw text would remain an insurmountable challenge for machine learning models, hindering their ability to extract meaningful patterns and insights.

Structured tokens allow models to understand and process textual data by converting words or subwords into numerical representations, which are essential for computational analysis. This structured format facilitates easier handling of large datasets and enhances the scalability of machine learning solutions.
Model Performance
Effective tokenization enhances the accuracy and efficiency of NLP models, leading to superior performance in tasks like sentiment analysis, machine translation, and text classification. By accurately segmenting text, tokenization ensures that models can capture the nuances and intricacies of language, resulting in more reliable and precise outcomes.
For example, in sentiment analysis, correctly tokenized phrases like “not good” versus “good” can drastically change the sentiment score assigned by the model. Accurate tokenization ensures that negations and context-specific meanings are preserved, thereby improving the model’s interpretative capabilities.
Handling Language Nuances
Tokenization aids in managing synonyms, homonyms, and context, ensuring that models understand the subtle nuances of language. This capability is essential for building models that can comprehend and generate human-like text, making interactions with AI systems more natural and intuitive.
Natural language is inherently complex, with words often carrying multiple meanings based on context. Proper tokenization helps disambiguate these meanings by preserving context, allowing models to better understand and respond to varied linguistic inputs.
Types of Tokenization Techniques
Tokenization is not a one-size-fits-all process. Different techniques cater to various NLP tasks and linguistic complexities. Understanding these techniques is vital for selecting the most appropriate method for your specific application.
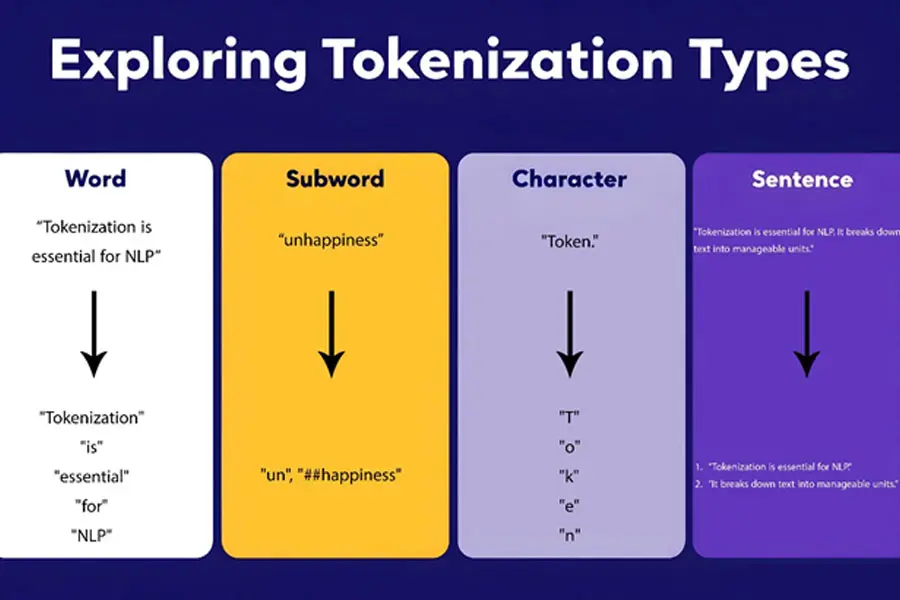
Word Tokenization
- Splitting text by spaces and punctuation
- Examples and use cases: Common in basic text processing tasks where each word is treated as an individual token.
Word tokenization is the simplest form of tokenization, where the text is split into individual words based on spaces and punctuation marks. This method is straightforward and widely used in applications like keyword extraction and basic text analysis.
Example: Consider the sentence: “Tokenization is essential for NLP.” Word tokenization breaks it down into:
- “Tokenization”
- “is”
- “essential”
- “for”
- “NLP”
- “.”
Use Case: Ideal for tasks where the focus is on individual words, such as bag-of-words models or frequency analysis.
Subword Tokenization
- Byte Pair Encoding (BPE)
- WordPiece models
- Benefits over word tokenization: Handles rare words and improves model robustness by breaking words into meaningful subunits.
Subword tokenization breaks words into smaller, more manageable units, allowing models to handle out-of-vocabulary words more effectively. Techniques like BPE and WordPiece are instrumental in enhancing the flexibility and accuracy of NLP models, especially in languages with rich morphology.
Example: Consider the word “unhappiness.”
- Word Tokenization: [“unhappiness”]
- Subword Tokenization (BPE): [“un”, “##happiness”]
Use Case: Essential for transformer models like BERT and GPT, where handling rare and complex words without increasing vocabulary size is crucial.
Character Tokenization
- Treating each character as a token
- Applications in language modeling: Useful for languages with rich morphology and for tasks requiring fine-grained text analysis.
Character tokenization involves splitting text into individual characters. This approach is beneficial for tasks that require a deep understanding of language structure, such as language modeling and text generation.
Example: Consider the word “Token.” Character tokenization breaks it down into:
- “T”
- “o”
- “k”
- “e”
- “n”
Use Case: Ideal for languages without clear word boundaries, such as Chinese or Japanese, and for tasks that require a high level of detail, like handwriting recognition.
Sentence Tokenization
- Dividing text into sentences
- Importance in contextual understanding: Enhances models’ ability to grasp the context and structure of larger text segments.
Sentence tokenization segments text into individual sentences, providing a higher-level structure for analysis. This technique is crucial for tasks that require understanding the context and flow of information across multiple sentences.
Example: Consider the paragraph: “Tokenization is essential for NLP. It breaks down text into manageable units.” Sentence tokenization breaks it down into:
- “Tokenization is essential for NLP.”
- “It breaks down text into manageable units.”
Use Case: Vital for tasks like summarization, question answering, and any application requiring comprehension of text at the sentence level.
Challenges in Tokenization
While tokenization is a powerful tool, it comes with its own set of challenges that can impact the effectiveness of machine learning models.

Ambiguity in Language
Dealing with homonyms and polysemy can complicate the tokenization process, making it difficult for models to discern the correct meaning. Ambiguity in language requires sophisticated tokenization strategies to ensure accurate interpretation and analysis.
Example:
- Homonyms: The word “bank” can mean a financial institution or the side of a river.
- Polysemy: The word “run” can refer to running a race, running a program, or a run in stockings.
Solution: Context-aware tokenization and leveraging surrounding words can help disambiguate meanings, allowing models to understand the intended sense.
Punctuation and Special Characters
Deciding which punctuation and special characters to include or exclude poses a significant challenge in tokenization. Proper handling of these elements is essential for maintaining the integrity and meaning of the text.
Example:
- Contractions: “don’t” vs. “do not” can be tokenized differently.
- Hyphenated Words: “state-of-the-art” might be treated as one token or split into multiple tokens.
Solution: Establish clear rules for handling punctuation based on the application’s requirements and ensure consistency across the dataset.
Multilingual Tokenization
Handling different languages and scripts requires versatile tokenization techniques that can adapt to diverse linguistic structures. Multilingual tokenization is particularly challenging due to the varying grammatical rules and character sets across languages.
Example:
- English vs. Chinese: English relies on spaces for word separation, while Chinese does not.
- Arabic vs. Russian: Different scripts and morphological complexities require specialized tokenization approaches.
Solution: Utilize multilingual tokenization libraries that support a wide range of languages and incorporate language-specific rules to handle unique linguistic features.
Slang and Informal Language
Processing social media and conversational text introduces complexities due to the prevalence of slang and informal expressions. Tokenizing such text requires models to recognize and appropriately handle non-standard language usage.
Example:
- Internet Slang: Words like “LOL,” “BRB,” and “IDK” may not be present in standard dictionaries.
- Emojis and Emoticons: Represent emotions and ideas that need to be tokenized and interpreted correctly.
Solution: Incorporate dictionaries of slang and informal expressions, and use tokenizers that can handle or translate emojis and emoticons into meaningful tokens.
Tokenization Tools and Libraries
Several tools and libraries facilitate tokenization, each with its own strengths and ideal use cases. Choosing the right tool can significantly impact the efficiency and effectiveness of your NLP projects.
Natural Language Toolkit (NLTK)
- Features and functionalities: A comprehensive library for text processing, offering various tokenization methods and tools for linguistic analysis.
NLTK is a widely-used Python library that provides robust tools for tokenization and other NLP tasks. Its versatility and extensive documentation make it a favorite among researchers and practitioners alike.
Example: Consider the sentence: “Tokenization is essential for NLP. It breaks down text into manageable units.” Using NLTK, it can be tokenized into words and sentences, making it easier to analyze and process.
Pros:
- Easy to use with a gentle learning curve.
- Extensive documentation and community support.
- Provides a variety of tokenization and preprocessing tools.
Cons:
- Slower performance compared to more modern libraries.
- Less efficient for large-scale processing.
SpaCy
- Advanced capabilities and speed: Known for its efficient performance and robust tokenization features, ideal for large-scale NLP tasks.
SpaCy excels in speed and efficiency, making it suitable for processing large datasets. Its advanced tokenization capabilities support a wide range of languages and complex text structures.
Example: Using SpaCy, the same sentence can be tokenized with additional context, allowing for advanced NLP tasks like named entity recognition and dependency parsing.
Pros:
- Highly efficient and fast, suitable for real-time applications.
- Advanced NLP features like named entity recognition, part-of-speech tagging, and dependency parsing.
- Supports multiple languages with dedicated tokenizers.
Cons:
- Steeper learning curve compared to NLTK.
- Requires more memory and computational resources.
Hugging Face Tokenizers
- Support for modern tokenization methods: Provides state-of-the-art tokenization techniques tailored for transformer models and deep learning applications.
Hugging Face Tokenizers offer cutting-edge tokenization methods that integrate seamlessly with modern transformer models like BERT and GPT. Their flexibility and performance make them essential for developing sophisticated NLP applications.
Example: For transformer models, Hugging Face Tokenizers can efficiently handle large vocabularies and complex tokenization schemes, ensuring compatibility and performance.
Pros:
- Optimized for transformer-based models, ensuring compatibility and performance.
- Highly customizable and extendable to support various tokenization needs.
- Active development and strong community support.
Cons:
- Primarily designed for developers with a strong technical background.
- Can be complex to set up for beginners.
Comparison of Tools
| Feature | NLTK | SpaCy | Hugging Face Tokenizers |
| Ease of Use | User-friendly | Requires some learning | Developer-centric |
| Performance | Moderate | High | Very High |
| Community Support | Strong | Growing | Extensive |
| Supported Languages | Multiple | Multiple | Primarily English and major languages |
| Advanced Features | Basic tokenization and analysis | Advanced NLP capabilities | State-of-the-art tokenization methods |
| Pros | Easy to use, extensive documentation | Fast, efficient, supports large-scale processing | Highly flexible, integrates with transformer models |
| Cons | Slower performance for large datasets | Steeper learning curve | Primarily geared towards developers |
| Ideal Use Cases | Educational purposes, basic NLP tasks | Large-scale NLP projects, industrial applications | Transformer-based models, deep learning applications |
Choosing the right tokenization tool depends on the specific needs of your project, including the scale of data, required speed, and the complexity of NLP tasks.
Applications of Tokenization in Machine Learning
Tokenization serves as the backbone for various NLP applications, enabling models to perform complex tasks with higher accuracy and efficiency.
Sentiment Analysis
Understanding opinions and emotions in text data by breaking it down into tokens for accurate sentiment detection. For instance, analyzing customer reviews on e-commerce platforms relies heavily on tokenization to discern positive or negative sentiments effectively.
Example: Consider a company analyzing thousands of customer reviews to gauge product satisfaction. Tokenization helps break down each review into meaningful words and phrases, allowing sentiment analysis models to accurately classify sentiments and identify key areas for improvement.
Machine Translation
Converting text from one language to another by tokenizing and translating individual tokens or subwords. Tokenization ensures that the nuances of both source and target languages are preserved during translation.
Example: A global company aims to provide multilingual support by translating user queries from English to French. Tokenization breaks down complex sentences into subwords, allowing translation models to maintain context and produce accurate translations, even for phrases or words not previously encountered.
Text Classification
Categorizing text into predefined labels by analyzing tokenized data, enhancing the precision of classification models. Applications include spam detection, topic categorization, and intent recognition.
Example: An email service provider uses tokenization to classify incoming emails as spam or non-spam. By breaking down the email content into tokens, the model can identify patterns and keywords associated with spam, effectively filtering unwanted messages and improving user experience.
Language Modeling
Predicting the next words or phrases in a sequence by leveraging tokenized text data for training sophisticated language models. Tokenization is fundamental for models like GPT, which generate coherent and contextually relevant text.
Example: Developing an intelligent writing assistant requires a language model capable of predicting and suggesting the next word in a sentence. Tokenization breaks down user input into tokens, enabling the model to understand context and generate accurate predictions, thereby assisting users in crafting well-structured and meaningful content.
Best Practices for Tokenization
Adhering to best practices ensures that tokenization processes are optimized for maximum efficiency and accuracy, leading to better-performing machine learning models.
Choosing the Right Technique
Align your tokenization method with project goals to ensure optimal performance and relevance to the task at hand. Different NLP tasks may require different tokenization strategies to achieve the best results.
Guidelines:
- Understand Your Data: Analyze the characteristics of your text data, including language, domain, and complexity.
- Task Requirements: Select a tokenization method that aligns with the specific requirements of your NLP task.
- Experimentation: Test multiple tokenization techniques to determine which yields the best performance for your model.
Preprocessing Steps
Effective tokenization often relies on thorough preprocessing. Implement the following steps to enhance tokenization effectiveness:
- Cleaning Text Before Tokenization: Includes lowercasing, removing stop words, and eliminating irrelevant characters to enhance tokenization effectiveness.
Example: Before tokenizing the sentence “Tokenization is essential for NLP,” convert it to lowercase and remove stop words to focus on meaningful tokens like “tokenization” and “essential.”
- Standardizing Text Formats: Ensuring consistency in text formats aids in more accurate tokenization and downstream processing.
Example: Converting all text to lowercase ensures that “Tokenization” and “tokenization” are treated identically by the tokenizer.
Post-tokenization Considerations
After tokenization, consider the following to maintain data integrity and model performance:
- Handling Out-of-Vocabulary Tokens: Implement strategies to manage tokens not present in the training data, such as using special tokens like <UNK> or fallback mechanisms.
Example: If a tokenizer encounters a rare word like “Xylofon,” it can replace it with an <UNK> token or break it down into known subwords, ensuring the model remains robust.
- Reconstructing Text from Tokens When Necessary: Ensure that tokenization does not hinder the ability to revert to the original text if needed for interpretability or other purposes.
Example: If you need to display the original text after processing, having a reversible tokenization process ensures accuracy and consistency.
Do’s and Don’ts
Do’s:
- Do perform thorough preprocessing: Clean and standardize text before tokenization.
- Do validate tokenization results: Regularly check tokenization outputs for accuracy.
- Do consider the context: Use context-aware tokenization methods for better understanding of ambiguous words.
Don’ts:
- Don’t ignore language-specific nuances: Tailor tokenization to the language and domain.
- Don’t over-tokenize: Avoid breaking text into too small units, which can lead to loss of meaning.
- Don’t neglect handling of special characters: Properly manage punctuation and symbols to maintain text integrity.
Tokenization in Advanced Models
Tokenization plays a critical role in the functionality and performance of advanced machine learning models, particularly transformer-based architectures.

Transformer Models
- Role of Tokenization in BERT, GPT, etc.: Essential for breaking down input text into tokens that transformer models can process and understand.
Transformer models rely heavily on sophisticated tokenization methods to parse and interpret input text. Proper tokenization ensures that these models can capture contextual relationships and generate meaningful outputs.
Impact:
- Subword Tokenization: Enables handling of out-of-vocabulary words by breaking them into known subwords, enhancing model robustness.
- Consistent Input Representation: Ensures uniform tokenization across different texts, facilitating better training and inference performance.
Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks (LSTMs)
- Impact of Tokenization: Tokenization affects how RNNs and LSTMs process sequential data. Proper segmentation ensures that these models can effectively learn dependencies over time.
Inaccurate tokenization can lead to loss of context and degrade the performance of sequence-based models.
Impact:
- Sequence Learning: Proper tokenization ensures that sequential models like RNNs and LSTMs can capture temporal dependencies and contextual relationships within the data.
Convolutional Neural Networks (CNNs) for Text
- Tokenization’s Role: In CNNs applied to text, tokenization determines the granularity of input data, influencing how convolutional filters capture local patterns and features.
Effective tokenization can enhance the model’s ability to recognize key phrases and n-grams, improving tasks like text classification and sentiment analysis.
Impact:
- Local Feature Extraction: Tokenization determines the basic units that convolutional filters operate on, directly influencing the model’s ability to detect local features and patterns within the text.
Contextual Embeddings
- How Tokenization Affects Word Representations: Influences the quality of embeddings by determining how words and subwords are represented in the model.
The way text is tokenized directly impacts the formation of word embeddings, which are crucial for capturing semantic meaning. Effective tokenization leads to more accurate and context-aware embeddings, enhancing overall model performance.
Impact:
- Semantic Richness: Proper tokenization ensures that embeddings capture the nuanced meanings of words and their contextual relationships, which is vital for tasks requiring deep understanding.
Efficiency and Performance
- Impact on Training Time and Resource Usage: Efficient tokenization can significantly reduce computational costs and accelerate model training.
Optimized tokenization processes contribute to faster training times and lower resource consumption, making it feasible to train large-scale models more efficiently.
Impact:
- Batch Processing: Tokenizing text data in batches rather than individually can leverage parallel processing capabilities, enhancing speed.
- Pre-tokenized Data: Using pre-tokenized datasets can reduce preprocessing time, allowing models to focus on learning patterns more quickly.
Comparative Performance Insights
| Model Type | Tokenization Technique | Impact on Accuracy | Impact on Training Time | Resource Consumption |
| Transformer Models | Subword (BPE, WordPiece) | High | Moderate | High |
| RNNs/LSTMs | Word Tokenization | Moderate | High | Medium |
| CNNs for Text | Hybrid Tokenization | High | Moderate | Medium |
The choice of tokenization technique significantly influences model performance across different architectures. Subword tokenization tends to offer higher accuracy in transformer models, while word tokenization is commonly used in RNNs and LSTMs.
Future Trends in Tokenization
The field of tokenization is continually evolving, with innovations aimed at addressing existing challenges and enhancing the capabilities of machine learning models.

Adaptive Tokenization Methods
- Dynamic Approaches Based on Context: Future tokenization techniques may adapt in real-time to the context of the text, enhancing flexibility and accuracy.
Adaptive tokenization aims to tailor tokenization strategies based on the specific context and requirements of the text, leading to more nuanced and effective processing.
Example:
- Contextual Awareness: Tokenizers that adjust token boundaries based on surrounding words or phrases to better capture contextual meanings.
- Real-Time Adaptation: Systems that modify tokenization rules on-the-fly based on input data patterns and user interactions.
Integration with AI Models
- End-to-End Models That Learn Tokenization: Developing models that can simultaneously learn tokenization and other NLP tasks, streamlining the workflow.
End-to-end models represent a significant advancement, allowing tokenization to be an integrated part of the learning process rather than a separate preprocessing step. This integration can lead to more cohesive and efficient NLP pipelines.
Example:
- Joint Learning: Models that learn token boundaries and semantic representations concurrently, improving overall understanding and generation capabilities.
Impact on Emerging NLP Technologies
- Influence on Conversational AI and More: Advanced tokenization will drive innovations in conversational agents, automated content generation, and other cutting-edge NLP applications.
As NLP technologies continue to advance, tokenization will play a critical role in enabling more sophisticated and human-like interactions with AI systems.
Example:
- Conversational Agents: Enhanced tokenization allows chatbots and virtual assistants to understand and respond to user inputs more accurately and contextually.
- Automated Content Creation: Improved tokenization techniques enable AI to generate coherent and contextually relevant content for blogs, articles, and social media posts.
Cutting-Edge Research and Innovations
- Neural Tokenization Models: Exploring neural network-based tokenization methods that learn optimal token boundaries based on contextual understanding.
- Zero-Shot Tokenization: Developing tokenization techniques that require minimal or no training data for new languages or domains.
- Cross-Lingual Tokenization: Enhancing tokenization methods to seamlessly handle multiple languages within a single model, improving multilingual NLP applications.
Example:
- Neural Tokenizers: Leveraging deep learning to create tokenization models that dynamically adjust to the context, improving accuracy and flexibility.
Tokenova Services
Tokenova’s integrated services ensure seamless tokenization and AI-driven solutions, empowering businesses to unlock the full potential of their data.
Overview of Tokenova’s Offerings
- Specialized Tokenization Solutions: Tokenova provides tailored tokenization services designed to meet specific machine learning and NLP needs.
- Custom NLP and Machine Learning Services: Beyond tokenization, Tokenova offers comprehensive NLP solutions, including text analysis, model training, and deployment.
Tokenova stands out by offering specialized tokenization services that cater to diverse machine learning and NLP requirements. Their expertise ensures that clients receive customized solutions that enhance their data processing capabilities.

Service Breakdown:
- Domain-Specific Tokenization: Tailored tokenization methods for industries like healthcare, finance, and legal.
- Multilingual Tokenization: Support for multiple languages and scripts, ensuring seamless processing across global applications.
- Real-Time Tokenization: Solutions that enable real-time text processing for applications like chatbots and live translation services.
- Scalable Tokenization Pipelines: Robust infrastructure to handle large-scale tokenization tasks efficiently.
Unique Value Proposition
- Cutting-Edge Technology and Expertise: Leveraging the latest advancements in tokenization and NLP, Tokenova ensures high-quality and efficient solutions for clients.
- Client-Centric Approach: Tokenova prioritizes understanding each client’s unique requirements, delivering solutions that are both effective and scalable.
- Continuous Innovation: Tokenova invests in research and development to stay ahead of industry trends, providing clients with state-of-the-art tokenization strategies.
Tokenova’s commitment to utilizing state-of-the-art technologies and maintaining deep industry expertise sets them apart in the competitive landscape of NLP service providers. Their innovative approach guarantees that clients benefit from the most effective tokenization strategies available.
Conclusion
Recap of Tokenization’s Importance
Tokenization is a cornerstone in the field of machine learning and NLP, enabling the transformation of raw text into structured data that models can effectively process and learn from. Its role in data preparation, enhancing model performance, and managing language nuances cannot be overstated.
Key Points:
- Data Preparation: Converts unstructured text into structured tokens.
- Model Performance: Enhances accuracy and efficiency of NLP models.
- Language Nuances: Manages synonyms, homonyms, and contextual meanings.
Final Thoughts
The role of tokenization in machine learning continues to evolve, driving advancements in text analysis and model performance. Embracing and mastering tokenization techniques is essential for anyone looking to excel in the dynamic landscape of machine learning and NLP.
Future Outlook:
- Adaptive Methods: Tokenization methods will become more context-aware and flexible.
- Integration with AI Models: End-to-end models will streamline tokenization within the learning process.
- Emerging Technologies: Tokenization will fuel innovations in conversational AI and automated content generation.
Key Takeaways
- Tokenization breaks down text into manageable units, enhancing data processing and model performance.
- Various techniques like word, subword, character, and sentence tokenization cater to different NLP tasks.
- Challenges such as language ambiguity and multilingual processing require sophisticated tokenization strategies.
- Advanced models and future trends are shaping the evolution of tokenization, making it more adaptive and integrated with AI technologies.
- Best practices in tokenization ensure optimal data preparation, model accuracy, and efficient performance.
Pro Tips for Advanced Practitioners
- Leverage Subword Tokenization: Utilize methods like BPE or WordPiece to handle rare words and improve model generalization.
- Customize Tokenization Pipelines: Tailor tokenization steps to fit the specific nuances of your dataset and project requirements.
- Monitor Tokenizer Performance: Regularly evaluate the effectiveness of your tokenization approach and adjust as needed to maintain model accuracy.
- Stay Updated with Latest Tools: Incorporate cutting-edge libraries like Hugging Face Tokenizers to benefit from the latest advancements in tokenization techniques.
- Integrate Tokenization with End-to-End Models: Explore models that learn tokenization alongside other NLP tasks for a more streamlined and efficient workflow.
- Implement Parallel Processing: Utilize parallel processing techniques to speed up tokenization, especially for large datasets.
- Develop Custom Tokenizers: Create custom tokenization algorithms tailored to specific domains or languages to enhance performance.
- Utilize Visualization Tools: Use visualization tools to analyze tokenization outputs and identify potential issues or improvements.
- Engage in Continuous Learning: Stay abreast of the latest research and trends in tokenization and NLP to continuously refine your skills and methodologies.
- Collaborate with Experts: Engage with the NLP community through forums, conferences, and collaborations to gain insights and feedback on your tokenization approaches.
These pro tips are designed to provide advanced practitioners with strategies to optimize their tokenization processes, ensuring their NLP models are both robust and efficient.
Glossary
- Token: The smallest unit of text, such as a word, subword, character, or sentence.
- Byte Pair Encoding (BPE): A subword tokenization technique that iteratively merges the most frequent pair of bytes in a dataset.
- WordPiece: A subword tokenization method used in models like BERT, which segments words into smaller, more frequent subwords.
- Polysemy: A single word having multiple meanings.
- Homonym: Words that are spelled the same but have different meanings.
- Embedding: A numerical representation of words or tokens in a continuous vector space.
- Transformer Models: A type of neural network architecture that relies on self-attention mechanisms, widely used in NLP tasks.
- Lemmatization: The process of reducing words to their base or dictionary form.
- Stop Words: Commonly used words in a language (e.g., “the,” “is,” “at”) that are often filtered out in preprocessing.
- Contextual Embeddings: Word representations that capture the context-dependent meaning of words in a sentence.
- Neural Tokenization: Tokenization methods that utilize neural networks to learn optimal token boundaries based on contextual understanding.
How does tokenization affect the scalability of machine learning models?
Tokenization directly impacts scalability by determining how efficiently large datasets are processed. Efficient tokenization reduces computational overhead, allowing models to scale seamlessly with increasing data volumes.
Can tokenization be applied to non-text data in machine learning?
While primarily used for text, tokenization concepts can be adapted for non-text data by breaking down complex data structures into simpler, analyzable units.
What is the difference between tokenization and stemming in NLP?
Tokenization involves breaking down text into tokens, whereas stemming reduces words to their root forms. Both are preprocessing steps but serve different purposes in text analysis.
How do transformer models utilize tokenization differently than traditional models?
Transformer models rely on sophisticated tokenization methods like subword tokenization to capture contextual relationships, enhancing their ability to understand and generate human-like text.
What role does tokenization play in reducing bias in machine learning models?
Proper tokenization can mitigate bias by ensuring balanced representation of words and phrases, reducing the likelihood of models learning and perpetuating biased patterns.
Are there any emerging tokenization techniques that leverage deep learning?
Yes, emerging techniques involve deep learning models that dynamically learn tokenization strategies based on contextual understanding, leading to more adaptive and accurate text processing.
How can tokenization improve the performance of a chatbot?
Tokenization enhances a chatbot’s ability to understand and generate human-like responses by accurately parsing user inputs and maintaining context within conversations.
What tokenization method is best suited for processing legal documents?
Subword tokenization methods like WordPiece are ideal for legal documents due to their ability to handle complex terminology and maintain context across specialized language.
Is it possible to customize tokenization algorithms for specific domains?
Absolutely. Customizing tokenization algorithms to align with domain-specific terminology and language patterns can significantly improve model performance and accuracy.
How does tokenization interact with other preprocessing steps like lemmatization and stop-word removal?
Tokenization is often the first step in preprocessing, followed by lemmatization and stop-word removal. Proper sequencing and integration of these steps ensure cleaner and more meaningful data for model training.