Healthcare in 2025 is more digital, more connected, and more exposed than ever.
Healthcare still has the most expensive data breaches of any industry. Recent analyses put the average cost of a healthcare data breach at about 7.42 million dollars in 2025, far above the global cross-industry average and still rising in severity.
A single incident can halt clinical services, trigger regulatory investigations, and permanently damage trust. At the same time, the same data that attackers target is exactly what hospitals, researchers, and AI teams need for life-saving work.
Healthcare data tokenization is a practical way to resolve this tension. It allows you to use sensitive patient information for analytics, research, and even Web3-driven models in the UAE, while keeping identities strongly protected and meeting HIPAA (the Health Insurance Portability and Accountability Act) and local privacy requirements.
What Is Data Tokenization In Health Data Privacy? – Consumer Laws For You
This guide walks through:
- Why tokenization in healthcare is different from other sectors
- How tokenization supports HIPAA and risk-based safeguards
- How HIPAA-safe tokenization works in practice
- Adoption trends and why the UAE is an important testbed
- How tokenization compares with encryption, masking, and anonymization
- A clear strategy you can follow to implement tokenization at scale
1. Why healthcare tokenization is different

In financial services, tokenization usually protects one or two fields, such as a card number. In healthcare, the challenge is much larger. A single patient journey can contain identifiers, clinical notes, diagnostics, images, prescriptions, insurance details, and data from apps or wearables. Almost every element can reveal something personal, and combinations of fields can re-identify a person even when obvious identifiers are removed.
That is why breach costs in healthcare remain so high. Recent industry roundups show that providers pay an average of 7.42 million dollars per incident, and they do so more often than any other sector. These events can disrupt surgery schedules, force staff back to paper, and leave patients fearful that their most private information is now out of their control.
Tokenization is tailored for this level of risk. Instead of leaving identifiers exposed across systems, it replaces them with random surrogate values. The clinical content remains available for analysis, but names, national IDs, and other key identifiers live in a separate, hardened environment. Analysts, data scientists, and AI teams can still use complete datasets. They simply work with tokens instead of raw identities.
For healthcare leaders, this shifts the privacy model. Rather than trying to protect every copy of every identifier, you protect a much smaller vault and use tokens everywhere else.
2. Tokenization and HIPAA: how they support each other
HIPAA does not tell you to use tokenization by name. It does something more demanding. It tells you to conduct a risk analysis, understand the threats to electronic PHI (Protected Health Information), and put safeguards in place that reduce those risks to a reasonable and appropriate level.
In practice, that means:
- You assess where PHI is stored, processed, and transmitted
- You evaluate the likelihood and impact of misuse
- You select controls that meaningfully lower that risk
Tokenization fits this framework very well.
Administrative, physical, and technical safeguards
HIPAA speaks in three main safeguard categories. Tokenization can strengthen all three.
Administrative safeguards
Policies can require that most staff and systems only see tokenized data. Only a small set of approved services can request re-identification. Every detokenization request is logged. This creates clear lines of responsibility and evidence for auditors.
Physical safeguards
The true identifiers live in a separate token vault. That vault is stored on secure infrastructure and isolated networks. If a laptop or local server is stolen, the data on it contains tokens, not real PHI.
Technical safeguards
Tokenization sits beside encryption and access control. It takes sensitive values out of general databases and replaces them with values that have no direct meaning. Even if attackers get past perimeter defenses, they see only tokens. Analysts of data protection now frame tokenization as non-reversible without a secure vault, which gives stronger breach resistance than encryption alone.
This is why many HIPAA specialists describe tokenization as a best-practice control once your risk assessment highlights high-risk PHI use cases such as large data lakes, AI training datasets, and third-party analytics.
3. How HIPAA-safe tokenization works
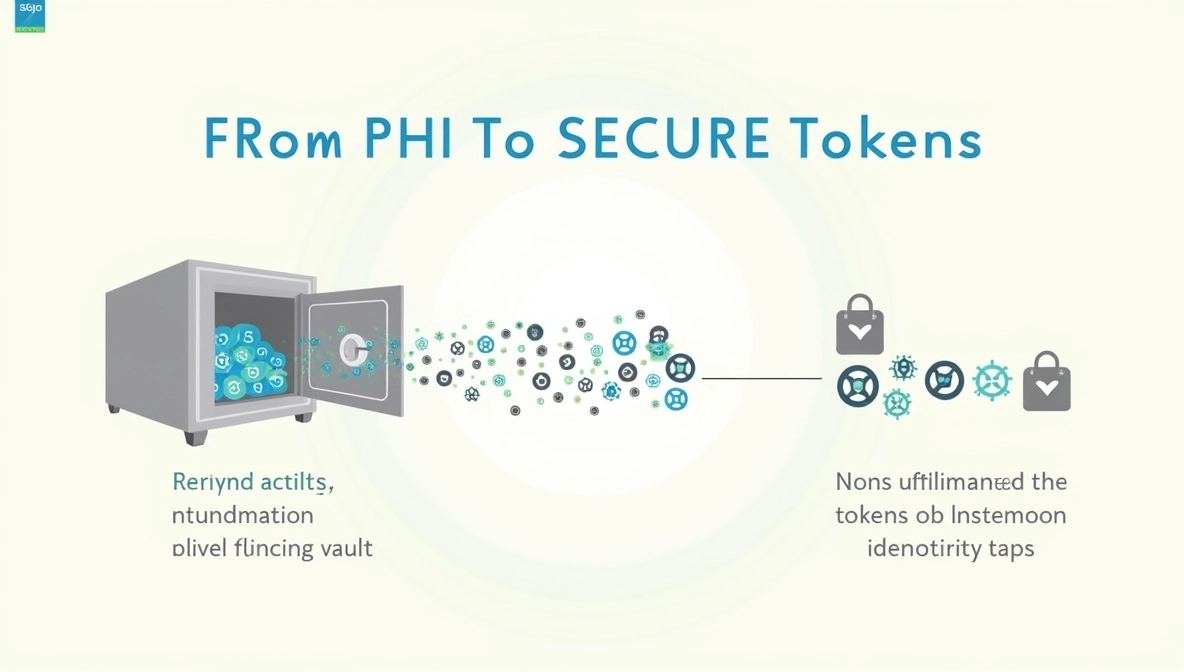
Tokenization in healthcare follows a simple idea with strict execution.
A system receives sensitive data, such as a medical record number or national ID. A tokenization service generates a random surrogate value and stores a mapping between the original and the token inside a secure vault. The calling system stores the token instead of the true value.
For example:
- Original value: 123-45-6789
- Token: SSN-TKN-5481-XYZ9
Outside the vault, there is no way to compute the original value from the token. There is no decryption key and no algorithm to reverse.
Only an authorized service, speaking to the vault under strict controls, can request detokenization.
Key design elements
A secure healthcare tokenization implementation usually includes:
A hardened token vault
The vault is a dedicated, encrypted data store. It runs on an isolated network segment. Only the tokenization service can talk to it directly.
Strong access control
Only selected backend services and limited roles can request detokenization. Access uses strong authentication and role-based authorisation. Requests are scoped to specific records or fields.
Comprehensive audit logging
Every tokenization and detokenization operation is logged with time, origin, and record context. Logs feed into security monitoring and support HIPAA and internal audits.
Non-reversible token creation
Tokens are generated by secure random processes or one-way functions. They may mimic the length or format of original values for compatibility, but they have no exploitable link to source data.
Because this architecture is complex and safety-critical, most healthcare organizations adopt specialised tokenization platforms rather than building their own from scratch. Those platforms integrate with EHRs (Electronic Health Records), databases, and analytics tools through APIs and typically include the controls described above.
In the UAE and GCC, tokenization platforms are also appearing inside national digital health programs and regulated innovation spaces, which allows teams to experiment with AI and Web3 data models without exposing live PHI.
4. Adoption trends and the rise of tokenization in the UAE
Tokenization has moved from theory into daily practice.
https://www.youtube.com/watch?v=DonJr6qt2I4
Industry research shows that the global healthcare tokenization market was valued at 548.2 million dollars in 2024, with forecasts of about 2.06 billion dollars by 2030. This implies 25.4 percent compound annual growth from 2025 onward. North America remains the largest region by revenue, but the same analysis notes that the UAE is expected to post the highest growth rate through 2030.
Clinical research is another clear indicator. Datavant reports that the number of trials using its tokenization technology has grown by about 300 percent since 2022, reaching around 270 tokenized trials by the end of 2024, and this is still increasing in 2025. Datavant+2AInvest+2 Sponsors now treat tokenization as part of the standard toolkit for linking trial data to real-world evidence in a privacy-preserving way.
The UAE is positioning itself as a leading testbed. The Dubai Health Data Sandbox, operated by Dubai Future Foundation and Dubai Health Authority, provides secure access to de-identified datasets, including EHR and claims data, for approved innovators. Commentary around the program makes explicit reference to tokenizing health data and, in some proposals, even exploring Web3 models where patients can benefit directly when their tokenized data is used.
For organizations based in or serving the UAE, this means tokenization is not only about HIPAA alignment. It is also an entry point into a broader ecosystem where health data, privacy, and programmable value flows meet.
5. Practical benefits and use cases

Tokenization earns its place when it solves real operational problems. Several domains benefit immediately.
Privacy-preserving research and real-world evidence
Researchers often need to link datasets from hospitals, payers, registries, and external sources. Direct identifiers are a barrier, both legally and ethically.
With tokenization, each record receives a consistent token across datasets. Analysts see full clinical content and can perform longitudinal and multi-site analyses, but they never see names or national IDs. If a trial sponsor later needs to contact a subset of patients, a controlled re-identification workflow can handle that step.
Recent work on tokenization in clinical research describes it as a preferred linkage method when future secondary datasets are still unknown at the time of study design.
Long-term outcome tracking
Outcomes often emerge years after treatment. Patients may change providers, insurers, or even countries. Tokenization offers a stable way to follow them in data.
A token can anchor all related events: admissions, lab results, imaging, prescriptions, and claims. Analysts can measure real-world performance and safety without storing identifiers in analytic systems.
AI and advanced analytics
AI models need scale. Imaging AI, predictive models, and digital twin concepts all rely on large, diverse datasets. Tokenization lets organizations share or pool such data for AI while keeping identifiable information sealed in the vault.
A radiology AI model, for example, might train on millions of images, each tied to outcomes and clinical context through tokens. No image file name contains a human name or ID. Tokenization in this context supports responsible AI, which is increasingly required by regulators and ethics boards.
Compliance, risk reduction, and non-production environments
By tokenizing PHI before it reaches test systems, training environments, and general data lakes, you reduce the number of systems in scope for strict regulation. Developers and data engineers work with realistic datasets that behave like production, but carry far less risk.
If a non-production database is exposed, it reveals only tokens. That can be the difference between a serious incident and a minor event with limited impact.
Patient trust and new participation models
Tokenization also has a communication value. It allows providers to say, with accuracy, that even internal analysts do not see patient names or IDs in most workflows. In markets like the UAE, it can support newer models where tokenized data feeds controlled data exchanges, with patients able to consent and participate in the value their data generates.
6. Challenges you need to anticipate
Tokenization is powerful, but it is not free. Four classes of challenges are common.
Technical complexity and skills
A tokenization platform touches core infrastructure, application logic, and governance. It demands skills in security architecture, database design, and privacy law. Many healthcare organizations do not have enough in-house expertise at the start and need partners for design and early implementation.
Integration into legacy and multi-vendor environments
Healthcare IT is often a patchwork of EHRs, billing systems, lab platforms, and custom data warehouses. Each interface may carry identifiers.
Introducing tokenization means revisiting data models, ETL pipelines, and message formats. Systems must know when to send a tokenization request and how to store and display tokens. This is feasible, but it requires patient planning and strong testing.
Performance and scaling
Every tokenization or detokenization request is an extra operation. If the design is weak, the vault becomes a bottleneck. That can slow clinical workflows or analytical queries.
To avoid this, organizations use high availability setups, caching for non-sensitive lookups, and sometimes vaultless patterns in narrow situations. Even then, tokenization remains a critical dependency that must be monitored carefully.
Governance and lifecycle
Tokens raise policy questions. How long do they remain valid? What happens if two patient records are later found to represent the same person? How do you respect deletion rights under GDPR, CCPA, or local UAE rules when data is spread across tokenized stores?
Clear lifecycle rules, regular reconciliations, and alignment with legal teams are necessary. Without them, token sets can drift and create compliance gaps.
Culture and change
Finally, tokenization changes how people see data. Analysts may resist losing access to identifiers. Clinicians may not understand why some fields now appear masked.
Communication, training, and transparent governance are key. Staff need to see tokenization as an enabler of safer data use, not a barrier to their work.
7. Tokenization compared with other protection methods
Tokenization sits beside encryption, data masking, and anonymization. Each has a distinct role.
Tokenization and encryption
Encryption scrambles data into ciphertext by using a cryptographic key. It is excellent for protecting data in motion and data at rest. If a key is stolen or mismanaged, however, the ciphertext can be turned back into readable form.
Tokenization removes the identifiers from general systems entirely. It substitutes them with tokens that have no algorithmic relation to the originals. Only the secure vault can map the token back. Even if a database is copied, the attacker does not gain PHI from the tokens alone.
Modern practice combines both methods. Data is encrypted at rest and in transit, and the most sensitive identifiers are also tokenized so that they do not appear in data lakes and non-critical systems at all.
Tokenization and data masking
Data masking replaces real values with realistic but fictitious values. Once masking is applied, the original values are gone. This is ideal for training environments, demos, and use cases where identity is never needed again.
Informatica and others describe masking as non-reversible, and they highlight that masked data is useful only for limited purposes, unlike tokenized data, which supports later re-identification.
Tokenization, in contrast, keeps a reversible link in the vault. It is closer to pseudonymization than full anonymization. This is better suited to research, AI, and operational use, where identity might need to be recovered under strict controls.
Tokenization and anonymization
Anonymization aims to remove the possibility of re-identifying individuals. It usually involves removing direct identifiers and also generalising or suppressing quasi-identifiers such as exact dates of birth or precise locations.
Recent guidance makes the difference clear. Anonymization is described as irreversible. Once data is anonymized, it cannot be linked back to a specific person.
Tokenization does not go that far. It hides identity for normal use, but the vault still holds the mapping. For regulatory purposes, tokenized data is treated as pseudonymized, not fully anonymized.
This distinction is important. Anonymization suits open data and public releases. Tokenization suits environments where you need privacy today but might still need to re-identify under governance.
8. A practical tokenization strategy for healthcare and the UAE
Tokenization works best when you treat it as a long-term program.
Step 1: Map risks and data flows
Start with a structured HIPAA-style risk assessment. List all systems that hold PHI, including obvious ones like EHRs and billing platforms, and less visible ones such as research databases and shadow spreadsheets. Document how PHI moves between them and across borders.
Include obligations from HIPAA, GDPR, and UAE rules. For example, Dubai Health Authority guidance stresses that health data generated in Dubai must remain within UAE borders unless specific conditions are met.
Use this map to see where tokenization will cut the most risk.
Step 2: Design an architecture that fits your reality
Define which identifiers to tokenize and where. Decide whether some tokens need to preserve format, so that legacy systems accept them, or whether you can use shorter or more compact formats. Consider a central vault pattern, and only use vaultless approaches in carefully controlled cases.
Plan for high availability, disaster recovery, and monitoring. Decide how long tokens will live, how to handle merges and splits, and how you will support deletion requests.
Step 3: Implement early in the pipeline and train people
Introduce tokenization as close as possible to the point where data enters your environment. New interfaces, imports, and APIs should replace identifiers with tokens before they land in general-purpose stores such as data lakes.
At the same time, train developers, analysts, and clinical users. Explain how tokenization protects them and the organization. Document how to request re-identification when it is justified, and how such requests are reviewed.
Monitoring should start from day one. Track performance, error rates, and access patterns to the vault.
Step 4: Choose the right partners
Decide whether you will work with a specialist platform or develop an internal solution. For most providers, a platform with healthcare experience, integrations for FHIR and DICOM, and clear HIPAA and regional compliance is the faster option.
In the UAE, use sandboxes such as the Dubai Health Data Sandbox to test your approach with regulators and innovation partners before full rollout.
Regardless of the route you take, assign clear ownership. Tokenization needs a home within security and data governance teams, not just within one project.
9. Conclusion
Healthcare data tokenization has matured into a central tool for patient privacy and regulatory compliance. It lets you keep PHI safe while still unlocking the insights that come from rich, connected data.
In 2025, this matters more than ever. Breach costs remain the highest in healthcare. AI and analytics demand more data, not less. Web3 and tokenization initiatives in the UAE and other forward-leaning regions are creating new expectations around data sovereignty and value sharing.
Tokenization sits at the intersection of these trends. It does not replace encryption, masking, or anonymization. It complements them. If you design it carefully, embed it into your data flows, and align it with HIPAA and local requirements, you can move from reactive compliance toward proactive, privacy-by-design healthcare.
You protect patients. You reduce breach impact. You keep regulators on your side. And you still give your teams the data they need to improve care and build the next generation of health services.
FAQ
What is healthcare data tokenization?
Healthcare data tokenization is a security process that replaces sensitive elements in patient records with random tokens. The real values are stored in a separate secure vault. The tokens keep data usable and linkable for research and analytics, but they do not reveal identity if a database is exposed.
Is tokenization required by HIPAA?
HIPAA does not list tokenization as a mandatory control. It requires you to assess risk to PHI and implement safeguards that are reasonable and appropriate. For environments with large volumes of PHI and complex analytics or AI use cases, tokenization is now widely recommended as a way to strengthen HIPAA compliance and reduce breach impact.
How is tokenization different from encryption in healthcare?
Encryption transforms data into ciphertext using a key. If someone gets that key, they can turn the ciphertext back into readable data. Tokenization removes identifiers from general systems and stores them only in a vault. The tokens have no mathematical relation to the original values. Only the vault can resolve them. This gives extra protection if attackers obtain copies of your databases.
Can tokenized healthcare data still support research and AI?
Yes. Tokenization preserves the clinical content and structure of records. Researchers can group records by token, link datasets, and conduct longitudinal analyses. AI teams can train models on tokenized data. They work with de-identified datasets that respect privacy, and re-identification is only possible for authorized workflows.
Where is tokenization used most in healthcare today?
Common uses include tokenized clinical trials, multi-site research networks, AI training datasets, data lakes that support population health analytics, and regulated innovation spaces like the Dubai Health Data Sandbox. In each case, tokenization allows high value use of data while keeping direct identifiers out of the main environment.